
- Vol.26-27
- 京都コンピュータ学院55周年・京都情報大学院大学15周年 記念式典・祝賀会を開催
- 躍動! 日本 I T団体連盟
- 初音ミクから学ぶデジタルコンテンツの可能性
- 新型コロナウイルスと持続可能な開発目標(SDGs)
- ニッツァ・メラス教授の京都案内
- KCGでMUΣA Live Show開催
- ジャパンエキスポに参加して
- 情報処理・ITで創る豊かな社会
- 日本のコンピュータ発展の歴史と情報処理学会の取り組み
- 親鸞聖人と私
- ITへの依存を高めるリスク管理
- モンゴルの雑誌“The Defacto Gazette”にキリル・コシック教授のインタビューが掲載
- 次代を担うIT人材育成へ活発に産学連携講義を開講
- 松田聖子の登竜門
- 私と吹奏楽
- 漢詩「哲学の道」
- 漢詩「暁庭聴鶯」
- 漢詩「三十三間堂」
- 卒業生インタビュー ヤンマー株式会社 中央研究所
- 卒業生インタビュー 株式会社イーパス・株式会社シードバンク
- ニュースこの1年「KCG365」
- KCGの浦山さんが情報処理学会で受賞
- インターネット関連の国際会議「ICANN64」に「.kyoto」のKCGIが参加
- 医療情報コースの学生が京都医療センターでインターンシップ
- 「救急災害医療」の特別授業を実施 第一人者の志馬先生から学ぶ
- KCGIからのSAP認定試験合格者が150人突破
- KCG創立者・長谷川繁雄初代学院長先生を偲ぶ「閑堂忌」
- 「KCGサマーフェスタ2019」を開催
- KCG共催の「京まふ2019」に大勢来場
- 移動体の自律走行を支援する高精度測位用基準局をKCGに設置
- モンゴルから来賓迎えKCGでシンポジウム開催
- 「ウィーンピアノ四重奏団演奏会」を開催
- KCG,KCGMの大槻幸雄顧問が日本自動車殿堂入り
- 『ドラゴンクエストX』『ニーア オートマタ』ゲームイベント開催に協力
- ソニーグループ企業によるIT業界セミナーを開催
- フランス総領事とマルセイユ市副市長一行がKCGI・KCG訪問
- KCGIがベトナム国家大学ハノイ校工科大学と交流協定を締結
- 2020年度からKCGI入学定員を600名に 開学時の7.5倍
- 授業料・入学金減免,奨学金支給の対象校に認定
- 訃報
- アキューム26-27(2021年発行)掲載広告
- Vol.25
- バイオ7からモンハンワールドへ KCG卒業生が開発の中心的役割
- アニメと日本と世界
- ジャパンエキスポに参加して
- 初音ミクがなぜ世界で支持されるか
- 日本ユニシスと締結
- 未来環境ラボを開設
- 未来環境ラボ技術交流会
- 京都医療センターと締結
- 京都医療センター見学記
- ポケットカルテ®を医療費適正化の切り札に
- 産業界において今後IT人材の果たす役割と必要なスキル
- ANIAが30周年
- 「KCGは京大が生んだ」長谷川繁雄 初代学院長先生を偲ぶ閑堂忌
- ICTによる社会のスマート化
- 臨場感の誕生:『ブリット』のカーチェイスの表象メカニズム
- 音楽を聴く楽しみについて
- パーソナルコンピュータ博物史の刊行によせて
- 地球の色彩り鑑賞・そら(宇宙)の旅
- 古を語る星ぼし⑦ 暦の計算法
- 集団人間行動と陶器
- 偶然購入した『沫若詩詞選』から見えてきたもの
- Welcome!KCG国費留学生
- KCG校友が京都大学で博士号を取得
- KCGI2017年度春学期学位授与式の最優秀賞は山中勇矢さん
- 漢詩「八達嶺長城」
- 漢詩「詠曼殊沙華」
- ニュースこの1年「KCG365」
- KCGが共催、京まふ大盛況
- プロが求める企画書とは?ゲームクリエイターによるセミナーを開催
- 恒例のKCGサマーフェスタ2017地域住民が多数参加
- 描いた絵と一緒に写真撮ったよ!京都水族館のKCGイベント人気
- KCGIからのSAP認定試験合格者が100人を達成
- 第一人者を招き「救急災害医療」の特別講義を実施
- ゲームエンジン『UnrealEngine4(UE4)』セミナーを開催
- チームラボによるIT業界セミナーを開催
- 米田貞一郎先生安らかに。「琵琶湖周航の歌」やコンサートで偲ぶ
- ロボット動いた!しゃべったよ!KCGで児童対象のプログラミング教室を開催
- インディーゲームフェス「BitSummit」を主催し、出展
- KCGIが韓国の大学等とeラーニング・MOOCの共同研究を開始
- 米国トップビジネススクールの一行がKCGを訪問
- KCGI学生チームがイマジンカップ日本大会に出場
- アキューム25(2018年発行)掲載広告
- Vol.24
- 日本IT団体連盟が誕生
- 情報社会の未来を切り拓くために
- 応用情報学への招待
- 長谷川繁雄初代学院長没後30年
- 新たにPDP-8/IとTOSBAC-1100D「技術遺産認定機器」に
- アメリカ映画と古い仏像
- 蓬莱と徐福
- 漢詩「豊国廟懐古」
- 漢詩「春日郊行」
- けいはんなからの新しいICTの波に乗り,次世代技術への興味を!
- 京都の品格・文化性を体現するよう安全安心な運営
- 古を語る星ぼし⑥安倍晴明の子孫たち
- 世界中の学生をつなぐ歌「君は花 僕は風」
- KCGの学生チームが性犯罪撲滅へアプリを開発し発表
- ディジタル情報の多様性を支える原理
- 訃報 米田貞一郎先生
- ニュースこの1年「KCG365」
- KCGとKCGIが京都府警と人材育成に関する協定を締結
- 「顧客の声聞き新IT展開を」。京情協講演で大元氏
- インディーゲームフェス「BitSummit 2015」を共催し出展
- KCGIが京都府と包括協定を締結,官学連携し京都ブランド発信
- IT声優コース学生に声優のKINAKOさんが指導
- 大連外国語大の学生がKCGIで短期研修
- ERP人材育成に向けKCGとKCGIがクレスコ社と協定締結
- 日本が僅差で台湾破る!CGアニカップに多数のファンがKCGへ
- 京情協,KCGIが企業情報セキュリティ支援ネットワークに参画
- 日本e-Learning大賞・ウェアラブル部門賞に輝いたKCGIを表彰
- 京都廣学館高校と連携協定を調印,出張授業を通じ生徒に専門教育
- KCGIがIPAの「IT起業家育成カリキュラム協力機関」に
- 2016年度からKCGI入学定員を240名に。開学時の3倍
- アキューム24(2016年発行)掲載広告
- Vol.22-23
- KCGグループ創立50周年
- 京都コンピュータ学院創立50周年・京都情報大学院大学創立10周年記念式典
- 式辞 京都コンピュータ学院・京都情報大学院大学統括理事長長谷川亘
- 祝辞 京都情報大学院大学 設立発起人 株式会社堀場製作所 最高顧問 堀場雅夫様
- 祝辞 ボスニア・ヘルツェゴビナ 特命全権大使 ペロ・マティッチ 閣下
- 祝辞 キルギス共和国 特命全権大使 リスベク・モルドガジエフ 閣下
- 祝辞 パプアニューギニア独立国 特命全権大使 ガブリエル・ジョン・クレロ・ドゥサバ 閣下
- 祝辞 京都府 副知事 山下 晃正 様
- 祝辞 京都市 市長 門川 大作 様
- 祝辞 韓国・大統領直属情報保護委員会 コミッショナー 韓国CSO協会 会長 李 弘燮 様
- 祝辞 京都大学 総長 松本 紘 様
- 祝辞 ロチェスター工科大学 プロボスト(筆頭副学長・副総長) ジェレミー・ヘフナー 様
- 祝辞 天津科技大学 副学長(学長代理) 張 愛華 様
- 記念講演会サイバーフィジカル世界でつくる「京都」美濃 導彦 氏
- 祝賀会
- 祝電・祝辞
- 記念行事
- 京都情報大学院大学 創立10周年記念式
- 最新OS Windows 8のストアアプリ開発
- グーグルがやろうとしていることと,ICTの新地平
- スーパーコンピュータ「京」10ぺタフロップスへの挑戦
- VFXと世界的パラダイムの変化
- ロボット時代の創造
- これからのものづくり〝中小企業の挑戦〞
- 全国同時七夕講演会@KCG-2013年の天文トピックスは大彗星到来
- 鉄道の音から電車運転士教育 システム・シミュレータまで
- コードの未来
- 歓迎アイソン彗星
- イノベーションは止まらない
- 中澤きみ子 ヴァイオリン・リサイタル 〜千の音色に思いを寄せて〜
- 三重奏の柔らかな調べ 「ウィーンのトリオ」
- 摩天楼オペラ 彩雨式 情報化社会と音楽について
- アメリカザリガニ平井のITって面白い!講座
- 若手ゲームプロデューサーズ!ゲームとITの未来
- ボカロとゆるキャラとアイドル 表現の進化系
- PCは娯楽の友!
- 御礼
- 京都コンピュータ学院創立50周年・京都情報大学院大学創立10周年記念式典
- 初代学院長の思い出
- 京都自動車専門学校がKCGグループに
- 京都マンガ・アニメ学会を設立
- 「京都国際マンガ・アニメフェア(京まふ)」共催
- ジャパンエキスポに参加して
- 「初音ミク」の生みの親・伊藤博之氏がKCGI教授に
- IT声優コース&マンガ・アニメコース新設
- 古を語る星ぼし⑤ 客星現る!
- 天文シンポジウム「歓迎 アイソン彗星」
- 「.kyoto」いよいよ2015年から運用開始
- 「MUΣA」コンサート by Nitza
- やさしそうに見える電話番号の難しさ 総務大臣賞を受賞して
- ANIA会長に本学の長谷川統括理事長が就任
- 「カワサキZの源流と軌跡」発刊
- 漢詩「新年作」
- 漢詩「詠大覚寺観月祭」
- KCGチームがマイクロソフト学生ITコンテスト Imagine Cup 日本大会で優勝!
- 京都情報大学院大学初代学長 萩原 宏先生が永眠 学校葬・追悼式を挙行
- 追悼文
- 電子計算機と共に歩まれた2の6乗年
- 情報工学の必要性を熱く語り,行動された萩原宏先生
- 追悼文
- 弔電
- 萩原宏先生を偲ぶ
- 萩原先生の短いコメントに込められた大切なもの
- 中国の文学や歴史に造詣が深かった萩原先生
- 萩原先生の思い出
- 萩原宏先生,有り難うございました
- ご恩に深く感謝
- 「KT-Pilot」の開発でご一緒
- 萩原宏先生を偲んで
- 夫婦ともどもお世話になりました
- 萩原先生の思い出
- 萩原宏先生,ありがとうございました
- 泉下から聞こえる柔らかくまた厳しいご叱声
- 教員転身への礎をくださった
- お菓子で団らんの後の本質突く「一言」
- 萩原先生,また季節の果物を持ってお話に伺います
- 萩原先生から学んだこと
- KT-Pilotのこと
- 新たな木の芽を生み出し,先生に報いたい
- 宇田敏彦先生 追悼
- 仙元隆一郎先生 追悼
- 植原啓之先生 追悼
- KCG365 2013 - 2014
- アキューム22号-23号(2015年発行)掲載広告
- KCGグループ創立50周年
- Vol.21
- Vol.20
- 誕生! 京都情報大学院大学 札幌サテライト
- ゲーム&アニメ
- ANIA京都大会・京都府情報産業協会 10周年記念大会
- 特集 東日本大震災
- 北海道バイク紀行
- カワサキZ1開発責任者・大槻 幸雄氏特別講演会
- 古を語る星ぼし③ 晴明の日食と今年の日食
- 卒業生登場 (株)Tryden 吉田鐘一さん
- 卒業生登場 (株)イビソク 木村寛之さん
- ゆとり教育で不足した学力はどこで補完するのか ~社会人になるために~
- 漢詩 「初弘法( 東寺、一月二十一日)」
- 漢詩 「秋日訪山寺」
- 服装について
- 初代学院長の思い出
- 実践WEBサイト奮闘記
- 老人ホーム見学記
- KCG365 2011
- NEAC-2206が「情報処理技術遺産」に認定。長谷川靖子学院長に感謝状
- 「NEACシステム100」KCGで4機種目の情報処理技術遺産・認定機器に
- 加藤真也さん(情報学科)がMashup Awards U‐23賞を受賞
- 前納一希さん(ネットワーク学科)は「スマートフォン選手権・アプリがいっぱい賞」で3位
- 日本がフランス破り優勝,3連覇! CGアニカップ開催、全国から多数の アニメファンがKCGへ
- 西アフリカのニジェールにパソコンを寄贈IDCE23ヵ国目
- マラウイ共和国駐日大使から,コンピュータ寄贈に対しての感謝の手紙が届く
- 12万円以上の善意,東日本大震災被災者へ 「青海大地震の際の恩返し」留学生らが支援バザー
- 閑堂忌に合わせ、恒例のサマーフェスタ 地域の方々とKCGが交流
- 長谷川利治先生 追悼
- さよなら山本武先生
- アキューム20号(2011年発行)掲載広告
- Vol.19
- 京の表情〜四季彩々
- 日本初「コンピュータ博物館」構想―第二章―
- 風の街 シカゴ
- 特集 学校連携
- 上野季夫先生が百歳
- 上野季夫先生 百寿によせて
- おかえり「はやぶさ君」~奇跡の生還
- 古を語る星ぼし② 浦島太郎とかぐや姫
- 世界標準となった日本の工業製品に学ぶ 川崎重工のZ1
- MICTIプロジェクトを振り返って
- 初代学院長の思い出
- 漢詩 「葵祭 路頭之儀」
- 漢詩 「山寺観楓」
- 米山さんがU-20プロコンで受賞
- 卒業生登場 (株)N.ジェン<東京都渋谷区> 西角 光人さん・岡本 匡史さん
- KCG365 2010
- 閑堂忌に合わせサマーフェスタ2010を開催
- KCGI学長に茨木俊秀氏が就任
- KCGIと韓国・国立済州大学校 デュアルディグリープログラム運営で調印
- 京都駅前校近くに イオンモールKYOTO がオープン
- パプア・ゴロカ大学に「KCG・ハセガワ・ラボ」開設
- アキューム19号(2010年発行)掲載広告
- Vol.18
- 特集 世界天文年
- 日食のはなし
- 世界天文年2009 ~ガリレオから学ぶもの~
- 過去未来の大日食
- 日本初「コンピュータ博物館」構想始動
- 日本初のコンピュータ博物館設立に向けて
- コンピュータ博物館の設立に期待
- コンピュータ博物館の設立について
- 『実物コンピュータ博物館』設立について
- 歴史的価値は確実に残し,教育に反映を
- 「日本初 コンピュータ博物館構想」に寄せて
- 技術を末永く後世に
- 博物館は教育施設としても活用を
- 世界で初めてノート型PCを開発 溝口 哲也氏 講演(要旨)
- 鏡の中の右と左
- 福建師範大学での講義
- 漢詩「早春賦」
- 漢詩「早春偶成」
- 百賀の祝い 米田先生が百歳 KCG一同で祝う
- 米田先生 百歳の誕生会に
- 古都逍遥 最終回 白河校周辺5 ~北辺を訪ねる
- 30年目のベルリン
- 寄贈パソコンが開く世界への扉 パプアニューギニア
- 「日本・ドナウ交流年2009」認定事業 ダンス公演『Dance of Death ~生きるよろこび~』
- 初代学院長の思い出
- 卒業生登場 「日本の標準」づくりへ邁進
- 卒業生登場 「起業家という生き方」
- 3年目を迎えたKCGブログ
- 若い感性,中小企業の力に 学生が府中小企業団体中央会のHP構築
- 全授業eラーニング対応 「休校」はせず 新型インフル発生受け「教育受ける権利」重視
- KCG卒業生 木村寛之さんが「日本情報考古学会 堅田賞」を受賞
- KCG保護者会が結成 サークルやセミナー活動で連携を密に
- 初代学院長に静かに手を合わせ 閑堂忌,記念イベントも盛大に
- 世界初,現役ウィーン・フィル奏者+舞踏コンサート ~IDCE 20周年記念~ クラシック音楽の歴史に画期的一歩
- KCG365 2009
- 学生さんとKCGのコンピュータ
- 小規模大学の将来像の一形態;ネットワークマルチバーシティ
- アキューム18号(2009年発行)掲載広告
- Vol.17
- 次の時代へ 新たな誓い 京都コンピュータ学院創立45周年 京都情報大学院大学創立5周年
- 記念式典 式辞 京都コンピュータ学院創立45周年 京都情報大学院大学創立5周年
- 来賓祝辞 堀場 雅夫氏
- 来賓祝辞
- 記念祝賀会(校友祭典)
- ハーバード大学からの祝詞
- コロンビア大学からの祝詞
- 祝電一覧
- IDCE 海外コンピュータ教育支援活動
- 記念イベント・記念講演会
- そして50年へ
- パイオニア・スピリット 新島襄の生き方から考える。
- 特集 IT業界が求める人材 IT人材の不足~現状と課題~
- 特集 IT業界が求める人材 未来のCIOを育てるために~企業のIT化の促進とCIOの必要性~
- 特集 IT業界が求める人材 IT人材の確保のために~全国ソフトウェア協同組合の取り組み~
- 特集 IT業界が求める人材 IT業界の現在
- 卒業生特集 (株)エヌ・ジー・アイ・エフ 代表取締役 松野誠さん
- 卒業生特集 バルーンネット(株) 代表 井上清貴さん
- 卒業生特集 マッチロック(株) 代表取締役 藤本文彦さん
- 卒業生特集 ベニックソリューション(株) 桂 義幸さん
- KCG京都駅前校への玄関口 変貌遂げる京都駅 相次ぐ商業施設整備
- 古都逍遥 白河校周辺4
- ~京都・異文化交流~ベーグルの魔法
- 京都で一番!―これはびっくり裏京都案内―
- 平安の天文家
- MDDロボットチャレンジ参戦記
- KCGI学長に長谷川利治氏が就任
- 洛陽総合高校,京都聖カタリナ高校と相次ぎ連携事業協定
- 「日本初」のKCGが全面支援 天津科技大に中国初の自動車制御学科
- 四川省大地震 故郷の被災者や復興に支援を 中国人留学生ら市内街頭で義援金集め
- 日韓間サイバーキャンパス実現 KCGIが国立済州大学校と調印
- 世界初,遠隔システムでチェコ・パルドゥビッツェ大学と学術教育交流協定を締結
- KCG365 2008
- 初代学院長の思い出
- 漢詩「述懐」
- 漢詩「喜天津再訪」
- アキューム17号(2008年発行)掲載広告
- Vol.16
- 卒業生特集「最先端の証」
- Q-GAMES キュー・ゲームス-会社紹介
- IT を YouT へ-株式会社日本システムディベロップメント
- KCG同窓会@東京
- 澤田さん
- 漢詩「庭梅開花」「船岡山懐古」「長城懐古」
- 詩を創る,唐詩を教わる
- 京都へ,おかえりなさい。
- 京都まち探訪 伏見
- 古都逍遥 白河校周辺3
- 京都のラーメン考
- ゲーム業界の求める人材を育成するために
- ゲーム業界で活躍する卒業生たち
- ダッカの豊かな子どもたち
- サラエボ紀行
- 済州島
- 天津にて
- RIT紀行
- 教育支援の輪 さらに拡大
- KCG 365 2007年
- 初代学院長の思い出
- 火星のクレーター Miyamoto
- オープンソースカンファレンスがKCGにやってきた!
- オープンソースソフトウェアの魅力
- アキューム16号(2007年発行)掲載広告
- Vol.15
- KCG style 2006 コンピュータの未来を探る
- スコット・ロス氏 特別講演会 「What is Reality?」
- 9時間耐久レースでKCG教職員チーム優勝
- 頑張れば,多くの人が支えてくれる 「kcg.edu」インテグラドライバー 伊藤 裕士さんが引退
- 情報セキュリティの現在 日韓越3ヵ国共同セミナー開催
- 日韓越3カ国共同セミナー パネルディスカッション セキュリティってなに? -健全なユビキタス社会の実現に向けて
- 韓国のユビキタス社会実現に向けたセキュリティ対策
- Security of PKI in Ubiquitous Computing
- マイクロソフトのセキュリティへの取り組み ~Vista OSのセキュリティを通じて~
- 「高度専門士」をご存知ですか?
- 長谷川 靖子学院長が(財)日本ITU協会より「国際協力 特別賞」を受賞―記念のピアノコンサートも
- 財団法人日本ITU協会からの国際協力特別賞受賞に際して―海外コンピュータ教育支援活動―
- 学術交流
- 古都逍遥 白河校周辺2
- 漢詩「看櫻」
- 若い時代を振り返って
- シラーの戯曲を読む
- さよならプルート 冥王星の76年
- 京を生きる プロをめざし京都へ 洋画家・中村晴信さん
- 場違いコラム
- 京都情報大学院大学が第1回学位授与式
- KCGI第一期生が「株式会社At Izumi」設立
- 卒業生紹介 ~株式会社インターネットイニシアティブ 白石陽介さん
- 学院を廻るアルティザンたち 劇団PASSIONE 豊嶋文香
- 鮨
- 初代学院長の思い出
- 初代学院長の思い出 特別編
- 詩があるじゃないか
- アキューム15号(2006年発行)掲載広告
- Vol.14
- 新館竣工・自動車制御学科開設に際して
- 京都コンピュータ学院 京都駅前校新館 設備紹介
- 建築家 寺下 浩 インタビュー
- F1の革新とコンピュータ
- Car IT時代のエンジニア養成を目指して
- ベトナムとの交流について ― ベトナム最大のソフトウェア開発会社と事業提携
- 日韓友情年の推進に向けて
- モザンビークICT学院プロジェクト JICA専門家派遣報告
- ダンス公演 京都府舞台芸術振興事業「海心遊記」に参加して
- 日本画を生きる ― 今中 恵
- 古都逍遥 白河校周辺
- 初代学院長の思い出
- 専門職業人教育の制度的由来について― 日本最初のIT専門職大学院の設置に関連して―
- 世界技術者会議2004 参加報告
- 竹田の岡城と全日本実年ソフトボール大会
- 漢詩「夏日郊行」
- 随筆 冬の実
- 相対論誕生百年と安倍晴明没後千年
- 曜日・干支の起源と計算法
- 宇宙一の力持ち-グレートアトラクター
- ゲームプログラマへの道
- 一台のパソコンから全てが始まる
- ITで経営をデザインする
- アキューム14号(2005年発行)掲載広告
- Vol.13
- 京都コンピュータ学院創立40周年記念式典
- 創立40周年記念式典 学院長式辞 時代を拓く情報処理技術者育成をめざして
- 京都コンピュータ学院 創立40周年に寄せて
- 学問の未来と国の未来を担うコンピュータ
- 京都コンピュータ学院 創立40周年記念式典 祝辞
- 京都コンピュータ学院 創立40周年記念講演 「時代を拓くパイオニア・スピリッツ」
- 京都コンピュータ学院 創立40周年記念講演 「なぜ日本の教育に改革が必要なのか」
- 京都コンピュータ学院 創立40周年記念講演 「平和教育への原動力としての情報技術(IT)」
- 京都コンピュータ学院 創立40周年記念シンポジウム 「歴史を揺るがした星ぼし」
- 京都コンピュータ学院 創立40周年記念講演 「未来を拓く超高速コンピュータ」―コンピュータに何ができるのか
- 日本最初にして唯一のIT専門職大学院 京都情報大学院大学 開学
- 京都情報大学院大学開学に向けて
- 京都情報大学院大学 開学記念式典
- 京都情報大学院大学 開学記念式典 理事長式辞
- 京都情報大学院大学 開学記念式典 学長挨拶
- 京都情報大学院大学 開学記念式典 来賓祝辞
- 京都情報大学院大学 開学記念式典 ロチェスター工科大学からのメッセージ
- 京都情報大学院大学 開学記念式典 コロンビア大学教育大学院からのメッセージ
- 京都情報大学院大学 開学記念式典 イリノイ大学アーバナ・シャンペーン校からのメッセージ
- 京都情報大学院大学 開学記念パーティー
- 京都情報大学院大学設立に際して
- 京都情報大学院大学の設備・概要
- 日本最初のIT専門職大学院で学ぶ
- 京都情報大学院大学「ウェブビジネス技術専攻」のカリキュラム
- 京都情報大学院大学 開学記念式典 メッセージ
- 京都情報大学院大学 開学記念式典 祝電
- 初代学院長の思い出
- 古都逍遥 京都駅前校の北辺
- 漢詩「夏日山居」
- 第3世代携帯電話アプリの開発とゲームデザイン― 日本と世界―
- NAIS発足式
- 小説 「雪見 -城崎にて」
- 校友祭典2003 Pioneer Spirit-KCG
- 創立40周年記念行事
- アキューム13号(2004年発行)掲載広告
- Vol.12
- 創立40周年記念の佳節を迎えて
- グローバルな教育ネットワーク
- 京都コンピュータ学院40年の歩み
- 京都コンピュータ学院 創立40周年記念行事スケジュール
- 私が見たモンゴル国
- 情報学 情報学科4年課程設置に際して
- デジタルシティと異文化コミュニケーション -社会情報学に向けて
- IT革命のパラダイムシフトと情報処理教育
- データベースの理論とその発展
- 情報学科が目指す教育
- The Internet2 - Dance in the Digital Age
- 学院NOW
- 大学崩壊と専門学校の優位性
- 中国のIT産業の現状と大学教育
- 日本語教育におけるオンライン教材の可能性
- 南アフリカ共和国・ヨハネスブルグ 「国連・持続可能な開発のための世界会議」レポート
- 宇宙の誕生と宇宙の未来
- 歴史を揺るがした星ぼし
- 携帯アプリ黎明期のゲームデザイン
- 40年前,日本人の大リーガーがいた!~マッシー村上~
- 古都逍遥 百万遍校周辺
- 初代学院長の思い出
- 漢詩「山寺観楓」「山寺観楓有感」
- ロバート・B・クッシュナー先生追悼
- 老師と大河
- Old Professor and The River (Dedicated to“Kush”)
- デジタルな音楽表現の長所と短所
- 学院を廻るアルティザンたち イラストレータ&CGデザイナー 今崎寛之
- 卒業生紹介 株式会社 CSK 松井博也氏
- アキューム12号(2003年発行)掲載広告
- Vol.11
- 米国同時多発テロに思う
- 京都コンピュータ学院ニューヨークオフィス崩壊当日
- 米国同時多発テロの現場から
- ハーバード・メモリアル・チャーチ 聖書の言葉と説教 2001年10月23日
- 我が都市 New York
- 米国同時多発テロから五ヶ月
- 大学に挑戦する専門学校―教育の危機・就職の危機こそ最大のチャンス
- Japan's System of Post-Secondary Education
- 日本の中等後教育制度(高等教育制度)(邦訳)
- 大学崩壊の時代―学校経営の視点から
- 21世紀のIT教育―本格的IT教育を目指して
- eラーニングの市場動向
- IT時代のプログラミング指南
- すばるをめぐって
- 第5回JAHOU集会を終えて
- KCGキャリア
- 学院NOW
- 初代学院長の思い出 ―思い出は尽きない
- 漢詩「冬夜偶成」
- 古都逍遥 鴨川校洛北校周辺
- コンピュータ・プログラムと著作権
- コンピュータの省エネルギー化
- 形状情報処理について
- ランドマークベースの音声認識において最適な指標を求める方法
- KCG RIT 姉妹校提携5周年を迎えて
- KCGとRITの友好関係を築いて
- 妖怪乱舞 陰陽座
- 学院を廻るアルティザンたち 映像作家 石橋義正
- 卒業生紹介 卒業生が最先端 藤井康彦さん
- アキューム11号(2002年発行)掲載広告
- Vol.10
- 巻頭言 21世紀を迎えて・・IT時代は「情報と頭脳」の時代 ―システムの創造的破壊とソリューション教育を―
- 中国,二大学との教育提携 日本語教育とコンピュータ教育の融合をめざして
- 月下独酌~NEW YORK~
- 地球温暖化研究の現状
- バリ紀行
- IT革命とはなにか
- わたしの考える「IT革命」 その虚実皮膜について
- 「専門家」から「非専門家」へ。―「非専門職」のススメ―
- インターネットと知的財産権法
- 中国のコンピュータ事情
- 海外で新米コンサルタント就職奮戦記 しなやかに あっけらかんと したたかに
- 初代学院長の思い出
- 知恵〔智慧〕の時代
- コミュニケーションのための―きく・話す―
- Y2K, on Z2
- 漢詩「緑陰讀書」「鴨川看白鷺」
- 陰陽師 安倍晴明の見た星
- 古都逍遥 京都駅前校周辺
- 世阿弥二題
- アートスペース紹介 ICC NTTインターコミュニケーションセンター
- はるかなるうみのはて
- 中島修彫刻展
- 卒業生紹介 古都京都に在る,小さな小さな大きい会社!
- アキューム10号(2001年発行)掲載広告
- Vol.9
- 創立35周年を迎えて(1998.11.18)
- 創立35周年記念イベント
- 創立35周年記念式典 パソコン贈呈式
- 海外コンピュータ教育支援活動 スリランカ
- 海外コンピュータ教育支援活動 ブルネイ
- 海外コンピュータ教育支援活動年表(1996年以降)
- 海外コンピュータ教育支援活動 北京・天津・西安
- 35周年記念座談会 新しい高速コンピュータの誕生―TOSBAC 3400 開発の思い出―
- 卒業生寄稿 情報化版 温故知新
- 卒業生寄稿 システムコンサルタントを目指す人達に
- 日本の私学と「専門学校」の概念
- 抽象の力
- 漢詩「初夏偶吟」「秋日郊行」
- 曲阜行 孔孟の跡を訪ねる
- コミュニケーションメディアとしてのコンピュータ
- ゲーム開発科の目指すもの
- 上野季夫先生と輻射輸達論の五十年
- 閑堂忌について-「一身独立の気力」-
- 初代学院長の思い出
- 木版画「人間の位置」
- 小惑星 Shotaro
- 五星聚井
- 21世紀の新文化首都 関西文化学術研究都市の試み
- 京都コンピュータ学院創立35周年記念イベント 最先端マルチメディアイベント
- 卒業生紹介 未知へのチャレンジ精神
- アキューム9号(1999年発行)掲載広告
- Vol.7-8
- 巻頭言 社会・文化の大変容期を迎えて ―文化としてのコンピュータ―
- 海外コンピュータ教育支援活動 ペルーへ
- アフリカ・中東・南米へひろがる海外コンピュータ教育支援活動
- 海外コンピュータ教育支援活動 メキシコからの研修生を迎えて
- 海外コンピュータ教育支援活動 タイ国マヒドン大学に滞在して
- 情報処理教育に求められるもの 4年制情報工学科の発足にあたって
- 二期制実施とカリキュラム改革
- インターネットの発展と私のホームページ作り
- 第15回京都コンピュータ学院卒業研究発表会
- 研究所だより
- 京都コンピュ-タ学院とオペレ-ションズ・リサ-チ
- ADEOS衛星搭載のPOLDERセンサ画像データについて
- 学院ニュース
- 初代学院長から伝えられた言葉
- 漢詩「惜花」「梅雨書懐」
- 詩とのつきあい
- 熊楠の手紙
- 宮沢賢治生誕百年に寄せる 「雨ニモマケズ」入門
- 「日本科学教育学会研究会」京都駅前校で開催される
- 世界最高速のコンピュータを作る
- シンポジウム「降着円盤の基礎物理」 天文の数値計算とコンピュータ
- 天文学のニュートレンド(降着円盤)
- 太陽とその活動
- 新惑星系の発見
- RITの日々
- R・I・Tと本学院との姉妹校提携実現に際して
- 芸術情報学科 学生CG作品
- 卒業生紹介 学院スピリッツ
- アキューム7-8号(1997年発行)掲載広告
- Vol.6
- 海外コンピュータ教育支援活動5周年を迎えて
- ポーランド日本情報大学の誕生
- ジンバブエ現地講習会報告
- ペルーへ向けてパソコン出発
- 対サウジアラビア王国支援 京都講習会
- 宇宙の果てに挑む ―新技術が拓く宇宙のフロンティア
- 出会い 中国の旅から
- 不変埋蔵の原理と動的計画の科学
- 不変埋蔵法とシステム同定
- ダイナミック・プログラミング
- 不変埋蔵法と生物医学への応用
- 遺伝アルゴリズムについて
- 研究所だより
- 有為転変 学院の設備更新に際し人材の育成を思う
- 夢のあるコンピュータの世界を
- システム創造のためのワープロ活用術
- 便利さと人間<性悪説>-個人情報保護のためのラディカルな問い
- 誰にでも使えるパソコン・BTRON~未来のパソコンのあるべき姿を見る~
- 初代学院長の思い出
- 京都コンピュータ学院校友会エグゼクティブクラブ結成式校友会長挨拶
- 京都コンピュータ学院校友会エグゼクティブクラブ国際協力事業推進委員会活動報告
- 就職難・リストラの嵐の前衛的突破法
- X線で見た宇宙
- 危ない小惑星
- 情報の天才-空海という人
- 卒業生紹介 情報化時代の啓蒙家
- アキューム6号(1995年発行)掲載広告
- Vol.5
- 巻頭言 学院創立30周年を迎えて
- 学院創立30周年記念特集 情報の哲学 21世紀のノヴム・オルガヌムを求めて
- 「人工知能と人間」(岩波新書)の著者,京都大学工学部教授長尾真氏に聞く。情報科学的視点は,世界をどう変えるか?
- 人間知性理解の二つの議論 -合理論と経験論
- 心の哲学について
- 孔子とのQAシステム
- 梅棹忠夫『情報の文明学』(中公叢書)を読んで
- 寧夏・内蒙の旅 留学生Y君に寄せる
- 研究への発想・発見・発明,意図した成果・意図せぬ発見,早過ぎる独創は権威ある大家も否定する
- 地上の実験室でクォーク・グルオンプラズマを造る-我々はビッグバン直後に到達できるか
- 狂言を語る 茂山千五郎
- 在京懐京(きょうにありてきょうをおもう) 京に老いてはシルバーシート?の巻
- 研究所だより
- モンタージュの魔術
- 「ナチ宣伝」という神話
- 認知の科学
- 認知革命?
- 脳とコンピュータ ―意識を持つ機械を目指して―
- 認知科学と人間の心理 ―機械の知が超えることのできない人間の知とは何か?
- 人工の目 移動物体識別追尾装置
- スキゾフレニアと世界のまなざし
- 茶碗の音
- 音声コミュニケーションの脳内メカニズム 人工知能が言葉を理解するためには
- 権力・文学・国家保安局
- 宮本正太郎先生をお偲びして
- 岩崎直子先生逝去 京都コンピュータ学院の支柱となった先生の功績と,その生命の永遠さを讃えて
- 初代学院長の思い出 とこしえの夢 ―前学院長,父との別れ―
- 星野恒彦句集「連凧」を読んで
- 漢詩
- 京都コンピュータ学院による海外コンピュータ教育支援活動 関連記事
- 対ケニア共和国コンピュータ教育支援活動 悠久なる大地ケニア
- 対ケニア共和国コンピュータ教育支援活動 花を咲かせる旅
- 対ケニア共和国コンピュータ教育支援活動 ナイロビ講習会
- 学院のみなさんJAMBO!! 京都短期留学 ケニア人研究者・教授16名
- ソフトウェア教育の改善を目指して
- ソフトウェア教育の発展を阻害するもの
- ガーナ共和国訪問記 行く河の流れは
- ガーナ共和国ケープコーストにヤスコ・ハセガワ・コンピュータセンター設立!
- 地球に近づく小天体
- 超新星とその残骸
- 宇宙背景放射とダークマター
- はくちょう座の星々-臨終の星が蘇る
- もう一つの国際交流 伝統文化継承に関する相互補完
- 卒業生紹介 学院スピリッツ
- アキューム5号(1993年発行)掲載広告
- Vol.4
- 京都駅前校舎大講堂の音響設計
- MESSAGE 学生達へ・・・
- 京都駅前校舎竣工記念フェスティバル
- 京都駅前校舎竣工記念式典・海外留学生研修オープニングセレモニー
- 京都駅前校舎竣工記念講演 国際化社会における日本の教育-世界の中の日本 期待される人間像をめぐって-
- 京都コンピュータ学院ボストン校創立者 長谷川由さん米国ハーバード大学大学院の卒業式で代表スピーチ
- 情報とは・情報化社会とは
- 「認知科学」へのいざない
- 情報教育懇話会 情報教育の現状
- 宇宙創世のロマン-アインシュタイン宇宙よりホーキング・佐藤の宇宙へ-
- 聖徳太子は南十字星を見た? 地球の首振り運動
- 生命とは
- 星間物質の化学と生命の起源
- 太陽系の有機物と生命の起源
- 地球生物の起源
- バイオの主役 DNAとは
- 遺伝情報の変化と発がんの機構 DNA修復
- 放射線治療に関連して 生体に対する放射線の影響
- 研究所だより
- 京の伝統芸能 能そして歌舞伎
- 教養としての伝統文化
- C&Cと高度情報化社会
- ヒューマン・インターフェイス
- 人にやさしいコンピュータを目指して
- ペン インターフェース PCについて
- 最先端技術とその応用
- 地球サイズの情報文化創造へ
- ガーナ印象記
- 対ガーナ情報教育振興事業 アクラ講習会
- 香港 ベルリンそしてワルシャワ
- ポーランド共和国文部省からの挨拶
- タイ・ガーナ・ポーランド 海外短期研修生を迎えて
- バートランド・ラッセル 教育論を読んで
- 初代学院長の思い出 京大音研
- 卒業生紹介 青年海外協力隊-ジャマイカ派遣を終えて
- アキューム4号(1992年発行)掲載広告
- Vol.3
- ほほえみのくに
- バンコック・パソコン講習会
- タイ・ベネフィット・ガラ
- タイ教員短期留学
- タイ視察旅行から
- 年間3600人のコンピュータ技術者を養成するために
- 対ガーナ情報教育振興事業について
- 対ポーランド情報教育振興事業について
- スーパーコンピューティングとシミュレーション天文学
- こんにちは星の赤ちゃん
- 宇宙の大規模構造
- パソコンのなかの惑星たち
- 知的財産権とコンピュータプログラム
- 初代学院長の思い出 よき時代の想い出
- 初代学院長の思い出 真の優しさ
- 情報の科学
- 情報科学をめぐって
- コンピュータ・ハードウェア技術の発展
- 情報化社会としなやかなシステム
- マルチメディア通信について
- 情報系システムに求められる知的支援を考える
- 連想記憶モデルによる情報の最適識別
- ニューロ理論の理解のために〈脳の働き〉
- ニューロ(神経回路網)理論による自動制御
- ファジィ理論と応用
- 三次元グラフィックスによる山岳景観の表示システム
- 考古学における土器文様とコンピュータ
- 放射線医用画像の解析
- イギリス文部大臣K・クラーク氏 京都コンピュータ学院を視察
- イギリスにおけるコンピュータと情報技術の高等教育
- 現代詩
- 地球温暖化の諸問題
- オーストラリア大陸縦断 ソーラーカーレースに参加して
- 世界の英語ハイク
- 常磐津を語る
- 京都の自然 海岸の松の緑を守るために幻のきのこ,松露を育てる
- 学院を廻るアルティザンたち-(3) Robert B.Kushner ロバート・クッシュナー
- 卒業生紹介 天草の禅寺コンピュータ和尚
- アキューム3号(1991年発行)掲載広告
- Vol.2
- 宇宙と俳句
- ボイジャー2号の見た海王星
- 宇宙ジェットSS433
- 京都コンピュータ学院による対タイ情報教育振興事業
- 同志社の創立者 新島襄と現代
- 若き日の長谷川繁雄初代学院長
- 1991年の惑星直列
- 悪徳商法雑感
- 世のなか,非線形
- 地球環境の科学
- グリーンハウスエフェクト
- マルチスペクトル衛星画像のコンピュータ解析による雲の研究
- マングローブ
- 衛星による地球モニターシステム
- 東南アジアの環境変化の一断面
- 京都コンピュータ学院NEWS
- 宇宙からの地球探査
- 人工衛星による地球画像の解析について
- 宇宙からの地球環境監視
- レーザーレーダーによる地球大気内のエアロゾル等の探査について
- 海洋探査と水色研究
- 高分解能人工衛星画像の領域分割と認識処理
- 「天文学的数字」ほどの情報処理
- 情報処理教育について
- バイオテクノロジーは何をもたらすか
- 現代中国 コンピュータ産業の現状と展望
- 現代詩
- 京都を語る
- 京都コンピュータ学院ボストン校設立の旨
- 第1回ボストン研修のはじまり -オープニングセレモニー
- 学院を廻るアルティザンたち(2) ロバート・メズベン
- 今後の情報処理技術者に求められること
- THE AUDIENCE
- アキューム2号(1990年発行)掲載広告
- Vol.1
- 創刊巻頭言
- 火星の極冠を計算する
- 火星の白雲の振舞い
- 恒星の固有運動
- 独立独行のひと 初代学院長の思い出
- 初代学院長の思い出
- 京都コンピュータ学院 創立25周年記念式典
- 25年! 熟成されたアイデンティティ 創立25周年記念式典学院長式辞
- 上空700kmからの視点 創立25周年記念式典式辞
- 京都コンピュータ学院は文化を創造する 創立25周年記念式典祝辞
- 学院の慧眼に敬服 創立25周年記念式典祝辞
- 先取りした精神と熱い情熱 創立25周年記念式典祝辞
- 国家試験合格者全国最優秀校としての事実 創立25周年記念式典祝辞
- 国際化に向かう先見性 創立25周年記念式典祝辞
- 創立25周年記念式典 記念講演(抄録)
- 創立25周年記念校友大会 朋友遠方より来る
- 創立25周年記念校友大会 また楽しからずや
- 創立25周年記念校友大会 協賛・協力企業一覧
- コンピュータ技術とその国際性
- 宇宙からの気象観測 スーパーコンピュータとともに
- 情報処理教育に求められること
- 現代詩 早稲田大学同人誌サークル「行李」より
- 都の四季
- 同志社(キリスト教学校)はこうして京都(神仏の街)に誕生した
- 映画のような町
- ショートストーリー Tに捧げるサーモンピンク
- 小面(こおもて)と乙(おと)-能と狂言-
- 対談「文化の交流」
- 学院を廻るアルティザンたち(1)キャロリーナ・デ・ウァールト
- 情報と文化のメビウス環
- 学園歳時記 学院プロモーションビデオ制作日記
- アキューム1号(1989年発行)掲載広告
- Extra
Accumu Vol.12
データベースの理論とその発展
寺下 陽一
1 データベース理論の始まりとその実用化
現代のデータベース技術はその中核部分が厳密な数学理論に基づいて発展させられてきたという点で,数多くあるコンピュータ/ITの諸技術の中でも非常にユニークである。もちろん,他の技術においても理論が使われていないわけではなく,例えばプログラミング言語の設計や実装においては言語理論が,また3次元グラフィックスにおいては微分幾何学を中心とする計算幾何学の理論が重要な役割を果たしている。更に,コンピュータの最も中枢にある論理回路はブール代数に基づいて設計されているのはよく知られた事実である。しかし,現代の関係型データベースについては,そもそもデータベースの為の理論が提唱され,発展させられてきたのである。すなわち,関係型データベースの定義から始まり,それに伴う代数系(関係代数)の理論,データベースの設計に関する正規化理論などがまず構成され,その抽象的な世界をITの現場で実用化するという過程をたどっているのである。これは素粒子物理学において,まず理論が提唱され,それを実験・観測によって実証するというプロセスと似た,理論先行型の技術分野ということができるであろう。
関係型データベースの理論は,IBM研究所研究員であったE.F.Coddが1970年に発表した有名な論文(A Relational Model of Data for Large Shared Data Banks)にその基礎を置く。データベースという言葉あるいは概念はそれ以前から存在し,それを企業情報システムの形成に利用するため様々な努力がなされてきた。「階層型データベース」,「ネットワーク型データベース」などのデータモデルが考案され広く実用化されてきた。しかし,これらのデータモデルは理論的な枠組みに基づくものではなく,現場の要請に応じて様々なデータ構造化手法が組み込まれてきたものである。その結果として,これらのデータモデルを基に実装されたデータベース製品(DBMS:DataBaseManagement System)は時と共にどんどん複雑化し,これらを利用するためには極めて熟練したプログラマが必要とされるようになっていた。
Coddの関係型データモデルは,数学でいう「関係」の概念に基づいたデータモデルである。すなわち,データベースに含まれるべきすべてのデータを複数個の表形式で表現し,これらの表を「関係」と見なすことにより,データベースを集合論的に定式化したものである。以前のデータモデルが,ポインタとか繰返し構造のような物理構造に伴う複雑な構成要素を持っているのに対し,関係型モデルは「関係」という構造のみに基づき,それ以外の構成要素を全く必要としない,極めて単純化されたものであったため,発表当時は関係者の間で非常に大きな反響を呼んだ。
しかし,この新しいモデルの有用性について大きな期待が寄せられたからといって,このモデルがすぐに実用化されるということにはならなかった。その理由として第一に,当時は既に階層型やネットワーク型データベースが実用化され,この方式のDBMS(IBM社のIMS,Cullinet Software社のIDMSなど)を提供するソフトウェア・ベンダーやこれらの製品を利用して情報システムを構築中であった企業ユーザは既に多大な人的資源と資金を投入していたため,これらの投資を無視して新方式のものに移行するということは到底不可能であったという事情がある。第二に,関係型モデルは高度に抽象化されたものであるため,これを実装するためにはソフトウェア技術上の困難があり,また当時のハードウェア(CPUと二次記憶装置)ではとてもパワー不足であったからである。
だからといって,実用化があきらめられたというわけではなく,Coddの所属するIBM社のサンホゼ研究所では彼の論文が発表された直後頃から実験用の関係型DBMSの製作に着手されていた。この実験用システムは”System R“と言い,このシステムで用いられたクエリ言語は SEQUEL と呼ばれていた。現在広く用いられているSQLの前身である。また,カリフォルニア大学バークレー校でも実験用システムの製作が進められ,これは INGRES と呼ばれていた。
IBMの実験システムは1980年代初頭に商業化され,SQL/DS,およびDB2という名称で市場に出されるようになった。カリフォルニア大学のシステムは1970年代の終わり頃に商業化され,実験システムと同名の INGRES という商品名で市場に出されるようになった。その当時の関係型システムは,(まだパソコンが普及する以前であったから)当然のことながら大型や中型のメインフレーム用のものであった。IBMのDB2の場合は,それ以前から同社から出されていたIMS(階層型DBMS)がまだ全盛であり,殆どのIBMユーザはこれを用いて情報システムを構築していたため,DB2はIMSと競合するような形になり,これらのユーザサイトにおいては少なからず混乱を引き起こした。
小型システム(パソコン)用の関係型システムは1980年代の後期になってから現れるようになった。PARADOX,dBaseIV,WATCOM-SQLなどが挙げられる。これらのシステムは「関係型」とはいうものの,厳密的な意味での関係型モデルには沿っていないものもあり,また,異なった製品間の互換性についても問題があった。しかしその後,本来的な関係型モデルへの忠実度は高くなり,同時に異なる製品間の互換性も著しく改良された。現在,Windows システムで一般的に用いられている ACCESS は関係型システムとしてかなり完成度の高いものである。一方,ネットワーク環境でのデータベース利用(クライアント・サーバシステム)に関しては,ORACLE システムが市場の大きなシェアを占めているのは周知のとおりである。
2 関係型データモデルの理論
関係型データモデルの理論では,データの集まりをすべて表(Table)の形で表すのを基本としている。ただし,理論的には「表」という言葉の代わりに「関係」という用語を用いており,厳密には「表」と「関係」は同じものではない。情報システムなどで対象となるデータはすべて複数個の関係として編成される。どのような関係を何種類編成すればよいか,すなわちデータベースをどのように設計すべきかは,「正規化理論」という理論によってその指針が与えられることになっている。「表」の代わりに「関係」という理論的に厳密な用語を用いると同時に,それに関連する他の概念も厳密に定義された理論用語が用いられる。表における「行」の代わりに「タプル」,「列」の代わりに「属性」,またデータ値に対して定義される「データ型」の代わりに「値域(ドメイン)」という用語を用いる。「関係はタプルの集合」であり,「関係の集合がデータベース」となる。
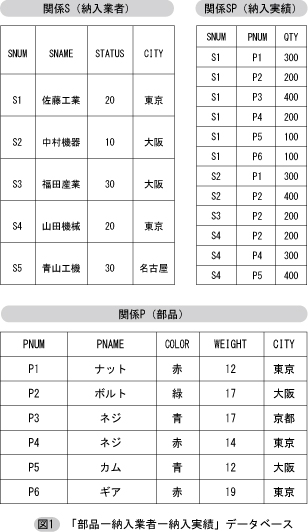
図1は有名なデータベースの教科書”An Introduction to Database Systems“(C. J. Date 著)で解説用に用いられる例題データベース「部品<S1, 佐藤工業, 20, 東京>,<S2, 中村機器, 10, 大阪>,・・・がタプルであり,この関係は5個のタプルから成っている。また,この関係は,SNUM,SNAME,STATUS,CITY という4個の属性を持っている。SNUMに対するドメインは「業者番号として可能な文字列の集合」,SNAMEに対しては「業者名として可能な文字列の集合」,STATUSに対しては「業者の状況コードとして可能な数の集合」(正の値のみ,おそらくは100以下),CITYに対するドメインは「日本の都市名の集合」となる。
これら関係については種々の演算が定義されており,このような演算の系は「関係代数(Relational Algebra)」と呼ばれている。演算には1個の関係を対象とする「単項演算」と,2個の関係を対象とする「二項演算」がある。また,これらの演算の中には従来の集合論で用いられ,よく知られているもの(Union, Intersection,Product 等々)と,関係データベース専用のものがある。もちろん,データベース理論にとって重要なのは後者である。これらの演算を用いてデータベースの検索(クエリ)を行うことができる。図1を用いて主要な演算の適用例を示してみよう。
まず,「選択」演算(SELECT)。これは単項演算であり,与えられた関係において指定されたタプルだけを抽出して新たな関係を作り出す。演算記号としてσ(シグマ)が用いられる。例えば,
σCITY= '大阪' (S)
とすると,図2(a)のような結果が得られる。(大阪所在の業者のみが抽出される。)
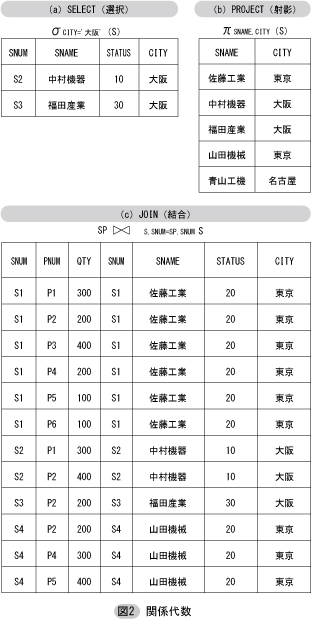
次に,「射影」演算(PROJECT)。これも単項演算であり,与えられた関係において指定された属性だけを抽出して新たな関係を作り出す。演算記号としてπ(パイ)が用いられる。例えば,
πSNAME,CITY (S)
とすると,図2(b)のような結果が得られる。(業者の名称と所在地のみが示される。)
実用上もっとも重要なのは「結合」演算(JOIN)である。これは2個以上の関係を共通の属性の値によって1個の関係に結合してしまうものであり,記号  が用いられる。図2(c)のように,
が用いられる。図2(c)のように,
SP S.SNUM=SP.SNUM S
にすると,関係SPのタプルと関係SのタプルについてSNUM値の等しいもの同士を連結した新しいタプルからなる別の関係が作られる。すなわち,元々のSPにおいては業者番号だけしかなかったのを,業者名や所在地なども一緒に示したいときにこの結合演算が用いられる。後に述べる関係モデルの正規化理論において,あるデータベースに属する関係はすべて冗長度が最小限(すなわち情報の重複が最小限)であることが要求されているため,冗長を含むような結果(理論的には業者番号だけで良いところを,業者名等の冗長な情報を含む)を求めるときにこの連結演算が欠かせないことになる。
データベースの検索を(理論的に)行うには,上記の関係代数の他に「関係計算(Relational Calculus)」と呼ばれる体系がある。これは人工知能分野でよく用いられる述語論理に基礎をおいたものであり,必要とする情報を探すための条件を記述するための記法を提供する。関係代数が「手続き的」言語と言われるのに対し,関係計算は「宣言的」言語と言われる。図3は関係計算(正確にはタプル関係計算)による検索の例を示す。

図3(a)は「大阪所在の業者を抽出せよ」というクエリを関係計算で表現したものである。tは個々のタプルを表す変数で「タプル変数」と呼ばれる。縦棒以降は抽出すべきタプルに関する条件である。S(t)は,「tがSに属する」という条件を示す。図3(b)は「部品P2を納入している業者を抽出せよ」というクエリである。この場合,それぞれSとSPのタプルを表すtとuという2個のタプル変数が用いられており,これら2個の関係を関連付けて検索する方法を示している。すなわち関係代数の場合の連結演算に対応するものである。記号∃は存在限定子と呼ばれる述語論理の記号であり,∃u(…)は,「…という条件を満足するuが存在する」という条件を示す。u.SNUM=t.SNUMという条件により関係Sと関係SPが関連付けられていることがわかる。
理論的な立場からいうと,関係代数を用いても,あるいは関係計算を用いても,どちらの方法でもデータベースの検索が可能である。実際,関係代数の検索能力と関係計算の検索能力は同等であることが理論的に証明されている。しかし,実用的な立場からいうと,一般のユーザがこのような数学的な記法には馴染み難いので,もう少し分かり易い検索言語が提案された。これがSQL(Structured Query Language)である。SQLは基本的には関係計算にのっとった宣言型(記述型)の言語であり,存在限定子∃も含まれている半面,関係代数の概念も取り入れられている。特に連結(JOIN)の概念はSQLに取り入れられているだけではなく,関係データベースの利用において中心的な役割を果たしている。
念のため述べると,SQLは単なる検索言語であるだけにとどまらず,データベース更新の為の諸機能,さらにデータベースの定義機能から管理機能をも含む大規模な言語体系となっている。
3 関係型データベースのための設計理論
Coddは当初の論文において,関係データベースの検索機能(関係代数,関係計算)の理論的定式化を示したのみではなく,データベースの設計に関する理論体系をも提案した。これはデータベースの正規化理論と呼ばれるものである。データベースの設計とは,構築中の情報システムに含むべきすべてのデータ項目を最も「望ましい」形の関係の集合として編成する作業ということができる。「望ましい」というのは, 「すっきりしている」,「意味が分かり易い」,「無駄がない」,といった言葉で言い換えることもできるのであるが,このような直感的な言葉を理論的に明確化しようとするのが正規化理論である。
正規化理論においては,設計を始める前は混沌状態にある多種多様なデータを段階的に整理していくが,この整理する過程を正規化と言う。正規化の達成度には何段階かある。最も弱い段階の第1正規形から始まって,第2正規形,第3正規形(Boyce-Codd正規形),第4正規形,第5正規形まで提案されている。理論的には第5正規形が最も望ましいとされるが,実用的には整理されすぎて関係の個数が多くなりすぎ,処理の手続きがかえって煩雑になる場合が多いため,通常は第3正規形で大体十分であるとされている。正規化を進めていく際の中心的な指針となるのが「関数従属性」の概念である。これはデータベースに含まれる種々のデータ項目間の意味的な(semantic)従属関係を明確にするものである。この従属関係を決定するためには,企業等の情報システム設計において対象となる種々のデータ項目の機能・役割を明確にし,それらの有機的な関係を分析する必要がある。
データベースの正規化(多くの場合,第3正規形)は実際のデータベース管理においてどのような意義を持つのであろうか。漠然とした「望ましい形」という直感的な要請を定式化することにより,実用上でも重要な効果を持つものであることが正規化理論で明確に示されている。適切な正規化処理をすることにより得られる主要な効果として,①種々の更新操作(挿入,変更,削除)を行う時に発生する可能性のある整合性違反を防止かつ制御できる,②不必要なNull値(未知データなど)の使用を回避し,集計計算やジョイン演算を円滑に行うことができる,③不適切なデータベース設計の場合に生じるジョイン不整合性を回避することができる,などである。
現在市販されているDBMSやシステム設計ツールの多くは,データベースの設定に際して正規形のチェックや正規化を支援するための機能を備えている。このような機能は,安定かつ管理の容易な情報システムを構築する際の大きな助けとなっている。
4 関係型データベースの発展と拡張
最初のCoddの論文が発表されて30年余,その間関係データベースはデータ管理技術の中核的な手段となり,多くの情報システムの構築において重要な貢献を成し遂げてきた。しかし,その間のハードウェアの高性能化,ソフトウェア技術の急速な発展,コンピュータ利用分野の飛躍的な拡大に呼応して,関係データベースの理論・技術についても様々な発展拡張がなされている。ここではその中から「推論型データベース」,「オブジェクト関係型データベース」,および「データウェアハウス」を紹介する。
4‐1 推論型データベース
先に述べたように,関係データベースにおける関係の操作(クエリ)は関係計算(Relational Calculus)によって完全に表現できることが証明されている。ところがこの関係計算は(一階)述語論理に基づいたものであり,これは人工知能分野の中心課題である推論機構の基礎となる理論である。従って,関係データベースに推論機構を組み込むことは非常に自然な機能拡張と考えることができる。
関係データベースを述語論理の枠組みで見ると,各関係のタプルは1個の事実(fact)を示している。例えば,Supply(納入する)という述語が定義されているとすると,
Supply (S1, P5, 100)
は,S1がP5を100個納入したという事実を示している。この3個の引数のうちいずれかを変数にし,例えば,
Supply (S1, P5, x)
とすると,これは「S1はP5を何個納入したか?」というクエリになる。このクエリに答えるには,この質問をユニフィケーションという操作を用いて必要なタプルを探し出すことになる。推論機構を可能にするためには,これに加えて規則(rule)を導入する必要がある。規則は変数を含む述語表現間に「if-then」型の関係で示される。これらの規則と事実を基にし,与えられた質問に対してユニフィケーションを反復(多くの場合,再帰的に)適用し,解答を探し出すことになる。これらの事実や規則,そしてクエリを表現するために,Datalogという言語が用意されているが,これは人工知能分野で以前から用いられてきたPrologの一種である。
推論型データベース用のソフトウェアとしては,LDL (Logic Data Language) ,NAIL! ,CORALなどがある。
4‐2 オブジェクト関係型データベース
オブジェクト指向パラダイム(OOP)に基づいたプログラミング手法,システム開発手法が広く用いられるにつれて,データベースに関してもこの種の手法に適応できるような機能が要求されるようになってきた。また,従来は企業等の日常業務(いわゆるトランザクション業務)に関連するデータを主目標として来たデータベース・アプリケーションがより複雑なデータを対象とするに従い,オブジェクトの概念をも包括できるようなデータモデルが必要となってきた。オブジェクト関係型データベースはこのような要請に応えて開発されたものであり,従来型の関係型データベースを拡張し,オブジェクトを扱えるようにしたものである。この種のシステムの例として,Informix Dynamic Server (IBM社)とOracleを紹介する。
Informix Dynamic Server (IDS)
IDSはユーザ定義のデータ型(OPAQUE, DISTINCT, ROW, COLLECTION),更にユーザ定義関数をサポートしているが,これらの機能をベースにデータ型の継承と,関数の継承が可能となっている。これに加えて,従来のDBMSでは対象とされていなかった特殊な複合型データを扱うために「データブレード」という機構を備えている。データの種類に対応して様々なブレード(Blade:刃)を用意しておき,安全カミソリの刃を取り替えるように,処理の対象となるデータに応じて専用のものをシステムに装着する方式がとられている。
この様なデータブレードが扱うことができる代表的なデータとして,以下のようなものがある。
①2次元図形(点,直線,多角形,経路,円など)。種々の設計図のデータベースに用いられる。
②画像データ(ビットマップ)。基本的な画像 処理用関数(回転,切取り,画像強調など)も組み込まれている。
③地理データ。GISなどで用いられる。
④時系列データ。株価の変動などを扱うことができる。
⑤大規模テキスト。フルテキストの文献検索などに利用される。
このデータブレードはユーザ定義も可能であるので,必要に応じて様々なものが作成され,ライブラリーとして利用できる様になっている。
Oracle
Oracleはバージョン8以降にオブジェクト機能を追加している。ユーザ定義のデータ型が可能で,データ型の一種としてオブジェクトを設定することが可能である。上で述べた複合型データなどはカートリッジという機構で組み込まれるようになっている。バージョン9ではこれらの複合型データも従来型データと全く同じ形式で操作できるようになっている。処理できるデータ型としてXML文書も含まれており,ウェブ上でのドキュメント転送が容易となっている。また,アプリケーション開発用言語としてC,C++,Java,COBOL,PL/SQL,Visual Basicが使えるようになっており,これら言語の持つOOP機能が,プログラムに埋め込まれたSQLとシームレスに動作できるようになっている。
4‐3 データウェアハウス
従来型のデータベースは業務データベース(トランザクション・データベース)とも言われ,日常業務で発生する様々なデータ照会,データ更新を迅速に,的確に,かつ正確に行うことを目標とするものである。従って,データは日常業務に直接関係するものに限られ,複雑性に関してもそれ程高いものではない。
一方,企業経営においては日常業務に直結するデータのみではなく,時間的に遡って現在では用いられていないものとか,地理的に広範囲にまたがるものを基にして様々な経営上の意思決定を行う必要が往々にして発生する。このような意思決定をサポートするシステムをDSS(Decision Support System)というが,これに用いられるデータは日常業務用データに比べて1桁も2桁も大規模なものになる。このようなデータを格納する機構をデータウェアハウスと呼んでいる。
データウェアハウスは業務データベースと異なって総合的な集計・分析に用いられるのが主目的であるので,それほど頻繁に更新される必要はない(いわゆる非活性型データ)。一般に,日常業務では既に用いられなくなった過去のデータをも含めて処理の対象となるのでデータ量は非常に大きくなる。また,頻繁な更新はない代わりに時間とともに累積的に増大していくのが普通である。データウェアハウスに収容すべきデータは一般に非常に多くの多様なデータ源から集められるのでフォーマットや記法を標準化する必要がある。従って,システムへの入力に際しては綿密な前処理・加工などが行われ,そういう意味で業務用データベースにおけるリアルタイム更新とかなり様子が異なり,バッチ処理的な更新操作となる。
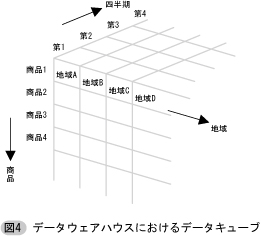
データウェアハウスのデータモデルの中心となる概念は,2次元のマトリックス,あるいは3次元以上の高次元のデータキューブといわれるメッシュ型のデータ表示方式である。データキューブの各次元(座標軸)には集計や分析のパラメータとなる項目(販売実績を分析する場合であれば,過去に遡る各四半期,商品項目,営業地域など)を割当て,各々のセルに対応するデータ値(売上実績など)を記録する(図4を参照されたい)。このデータキューブは様々な次元(座標軸)に沿って見る(その次元に関して射影をとる),それらの次元について部分的に圧縮する(ロールアップ,すなわち個々の商品の代わりに商品区分単位で小計を見るなど),あるいは部分を展開して詳しい表示をする(ドリルダウン)といった操作が可能で,様々な視点,視野からの分析ができるようになっている。
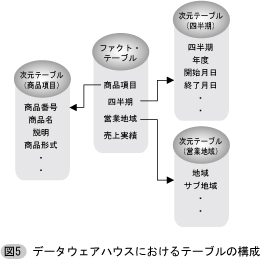
このデータキューブのデータ値は2種類のテーブルによって管理されている(図5を参照されたい)。その一つはファクト・テーブルと呼ばれ,表示の対象となるデータ値を収容すると同時にそのデータ値の由来となるパラメータ値(四半期,商品項目,営業地域などの各次元)への参照値(ポインタ)を含んでいる。これによって参照されるパラメータ値は実際にはいくつかの項目からなるタプルであって,パラメータの種類の各々に関してテーブルとして与えられている。これらのテーブルは次元テーブルと呼ばれている。次元テーブルには個々のパラメータ(例えば商品項目)に関する詳しい情報が収容されている。
データウェアハウスが確立されると,それを基にOLAP(On-line Analytical Processing)システム,データマイニング・システムなどが構築され,高度の経営判断のサポートに活用されることになる。
5 おわりに
筆者がCoddの関係データベース理論に初めて接したのは,1976年から三年計画で進められた文部省特定研究「情報システムの形成過程と学術情報の組織化」に参加した際であった。この研究グループは当時の日本の代表的な情報工学・情報科学の第一線の研究者がすべて参加するという国家的なプロジェクトであり,そこで行われた研究は情報工学・情報科学の実に広範な分野を含むものであった。しかし研究テーマの性格からして中心的な課題はデータベースに関連するものであり,グループの研究者たちの関心は何と言っても当時としては最新のCoddの理論であった。この理論を早急に修得しなければならないということで,リーダーの1人である北川敏男先生の号令の下,グループの全研究者による勉強会が始められた。その時用いられたのがC.J.Dateの教科書である。当時のトップクラスの研究者(現在では日本の情報分野の重鎮の先生方)が,大学院生の勉強会さながらにセミナー室に缶詰になって汗を拭き拭き読み合わせをしていたのが思い起こされる。この教科書も現在では第7版となっており,今年(2003年)の夏ごろには第8版が出るとのことである。第1版に比べるとページ数は3倍以上になっていようか,その間のデータベース研究の発展が凝縮されている書物である。